Designing A Workflow Engine from First Principles

swyx
Video: Designing a Workflow Engine
This is an annotated summary of a talk given at the Systems @ Scale 2021 conference hosted by Facebook. Prior talks focus on the programming model of Workflow as Code, but this talk focuses on common requirements that you will want out of any workflow engine:
- Task Queues
- Timers
- Consistency
- Scalability
- Sharding and Routing
- System Workflows
- External Workflow and Activity Implementations
We offer a discussion of how Temporal solves these requirements, but the hope is that you will better understand workflow engines from first principles.
Context: History of Temporal (0:15)
- Temporal was not an overnight idea. It took at least 15 years to get to where we are.
- Circa 2004, Maxim was tech lead of the Amazon messaging platform when Amazon was transitioning into microservices. This was later used by Simple Queue Service when AWS was launched. Maxim was also the tech lead for the Simple Workflow service (SWF) which spawned a lot of ideas that are now part of Temporal.
- Samar also worked on SWF, but later joined Microsoft and became tech lead for Azure Service Bus. As a side project, he wanted to bring to the people the same ideas of SWF, so he developed the Durable Task Framework, which became so popular that it was adopted by the Azure Functions team. You can now use it as Azure Durable Functions.
- Samar and Maxim both joined Uber, and built two open source projects: Cherami (a messaging system) and, later, Cadence (an open source implementation of SWF ideas using a completely different software stack).
- When Cadence became very popular, not only inside of Uber where >100 usecases were running on it within 3 years, as well as outside, they quit Uber and started Temporal. Temporal is a fork of Cadence as a separate open source project.
- Temporal has gained some great early adopters, and we count Hashicorp, Box, Checkr, Datadog, and Doordash just among those that have been public about their usage.
The Four Properties of a Workflow (2:52)
What is a workflow?
Our definition is that a workflow is a:
- Resilient Program, that
- Executes Tasks, and
- Reacts to External Events, including
- Timers and timeouts
Resilient means that the program will continue execution despite failures (like infrastructure outages and availability zones going down).
Usually this program is organized as a sequence of tasks and it also has to react to external events and deal with time. Timers and timeouts are an important component of every business level process.
Temporal's Programming Model (3:40)
The basic idea of Temporal is that you "just write code", as in this Java sample:

We also support Go, PHP, and other SDKs (TypeScript and Python are in the works).
This looks like normal Java code, but it is a workflow because the state of the program is fully preserved at all times.
- If your program restarts or the backend service goes down, your program will be in exactly the same state with all local variables and stack traces in exactly the same state.
- You can call sleep for 30 days in your code without caring about process restarts or dealing with databases and state recovery, because that is done automatically by Temporal.
Maxim and Samar have given multiple presentations on the Cadence and Temporal programming model over the past 4 years if you want to learn more.
Workflow as State Machine (5:15)
At a high level, any workflow engine (including those that use Workflow-as-Code like Temporal, or those that use YAML/JSON/XML) are state machines. You need a state machine to define which order to run tasks and to react to external events.
You can represent it with a sequence diagram like this:

But to implement the workflow engine you need a core that will drive these workflows:

Walking through the diagram:
- the engine gives the current state to the WorkflowDefinition state machine
- the WorkflowDefinition returns what the next commands are to run
- the first command is to run Task1, so it does
- then the engine notifies the WorkflowDefinition that Task1 is completed
- again, we execute the state machine logic according to its definition and find the next command
- the next command is to run Task2,
- and so on.
Using Task Queues (6:00)
In practical systems, you don't want to call tasks directly, because there can be issues with flow control, availability, or slowness. So using queues to dispatch tasks is a very common technique.

Every practical workflow engine uses queues to dispatch tasks to workers (working processes that host those tasks).
Timer Queue (7:10)
Time is important because:
- every task invocation should have a timeout
- the workflow itself can time out
- you need to be able to execute operations like sleeping for 30 days
So you also need an external timer service or timer queue that durably stores and dispatches these timers.

Consistency and the importance of Transactions (7:35)
We need to store the state of the workflow so that every time we start a workflow, we:
- create state in the database
- create a timer
- pull tasks from the task queue for the WorkflowDefinition to pick up
- when it gives a list of commands we need to update and create tasks and update the state
These updates across multiple data sources must be transactional.

If you only remember one slide from this presentation, remember this one.
If you run atop a workflow engine that doesn't have transactions across all these components, you will run into all sorts of race conditions:
- if you update state, and put tasks in task queue, and the state update goes through, but the task queue update fails, your system ends up in a state where it thinks there is a task outstanding but the task is not.
- if you put tasks in a task queue first and then update state, then If your update is slow, the task can be delivered and processed by the time that goes through so it will be inconsistent and need to deal with edge cases
If all these updates are transactional, then all these race conditions disappear. The system becomes simpler and application level code doesn't see all these edge cases and it simplifies the programming model.
This doesn't just apply to the workflow engine implementation. Most engineers don't use workflow-like orchestrators or workflow-engines to write their services. They use queues, databases and other data sources to create hodgepodge architectures with no transactions across them:

Our point about lack of transactions leading to race conditions applies to the majority of ad hoc systems built by developers.
This is very important to understand: If you are building a system from these components you're guaranteed to have edge cases in race conditions. So that's why having a robust engine with something like Temporal's underlying architecture will simplify your life tremendously.
Scalability Needs (10:30)
Workflow engines are hard because they need to deal with multiple things like task queues, timers, and state, and transactional updates across them all. When you look for workflow engines with these requirements, many implementations just use one database or even one process. If that is all you need, then the transactional requirements are easily solvable. But it wouldn't be scalable.
What dimensions of scalability are important to us? How would we execute a million tasks?
We could naively create a single huge workflow that spawns multiple machines, e.g. MapReduce lets you write a single pipeline executed by thousands of machines. However, Temporal chose a different direction.
- Workflow as unit of scalability. For Temporal's target usecases, we decided not to design for scaling up a single workflow instance. Every workflow should be limited in size, but we can infinitely scale out the number of workflows.
- So if you need to run a million tasks, don't implement them all inside a single workflow, have a single workflow that creates a thousand child workflows, each of which run a thousand tasks. This way, each of the instances will be bounded.
- Multiple Hosts. Once we can assume each instance has a limited size, we can start distributing them across multiple machines. Scaling out a fleet of machines becomes practical because each instance is guaranteed to fit within a single machine.
- Multiple Stores. If you want to have a very, very large system, you need to scale out the database as well. A single database instance will be a bottleneck.

If you can handle a partitioned database and partitioned hosts you can get to a very scalable solution. The key problem here is we need to maintain transactionality - as soon as you start breaking persistence into multiple databases you would not be able to provide those guarantees, unless you do complex things like two-phase commits.
Sharding (12:38)
The simple way to solve the partitioning problems would be to simply have one database per host and guarantee transactions within each host - but this wouldn't be very practical because it would be very hard to add and remove hosts.
The standard way to solve this is to use sharding. Instead of physical hosts, we:
- use partitions within the database,
- over-allocate the number of partitions,
- allocate those partitions to specific physical hosts, and
- move them around if necessary.
The same applies to shards within our hosts: you can hash workflows to a specific shard id and use consistent hashing to allocate a shard to a specific host.

Membership and Routing (13:50)
To implement sharding, you need to know the membership of your cluster. If you need to allocate shards to hosts, you need to know which hosts are available in your cluster. So as soon as you do that you need some mechanics for membership.
You also need a routing layer. You don't want to have a fat clientside library that understands the topology of your cluster, so you will need to have a frontend which will know the membership of the cluster and route requests accordingly.

The Task Queue Problem
Sharding by workflow ID works, except for task queues. For example if you have activities which listen on a task queue named foo, how do you get activity tasks waiting to be executed? If you store those activity tasks in every shard, you need to go to all shards and ask if they have anything for task queue foo . If you want to allocate a large number of shards, these kinds of queries become impractical. We cannot even aggregate them over hosts because each shard requires a separate database query. Imagine if you have 10,000 shards, and every time you do a pull you fan out 10,000 database requests.
So a practical solution is to move the queue into a separate component with its own persistence.

That solves the problem of routing, but it introduces other problems: as soon as queues live outside of core shards of workflow state, we don't have transactions across them anymore.
Local Transfer Queues (16:15)
One way to solve that would be to use some sort of two-phase commit variant like Paxos or Raft, but it would introduce significant complexity to the system and require every participating component to implement complex protocols.
The way we solved it in Temporal is using Transfer Queues.
The idea is that every shard which stores workflow state also stores a queue. 10,000 shards, 10,000 queues. Every time we make an update to a shard we can also make an update to the queue because it lives in the same partition.

So if we need to start a workflow, we:
- create a state for that workflow
- create workflow tasks for the worker to pick up
- add the task to the local queue of that shard
- This will be committed to the database atomically
- a thread pulls from that queue and transfers that message to the queuing subsystem.

This way we have transactional commits with a later transfer to the queueing subsystem. (This transfer could fail and retry so duplicates can occur, but we have a separate part of the system which will do the deduping)
So this is a very simple mechanism that allows transactionality, but doesn't rely on complex two-phase commit protocols.
Note: This is also known as the transactional "Outbox" pattern.
Workflow Visibility (17:35)
The other requirement that a reasonable workflow system should implement is the ability to list workflows, e.g. "give me all workflows started by $USER in the last 24 hours that failed".
Going to all 10,000 shards and asking for this information, even with indexing, would be impractical. The way to solve this is to have a separate indexing component.

Any indexing technology could work; we use Elasticsearch because it is open source.
We use the same transfer queue approach to commit "visibility records" into each shard and use the transfer queue to transfer them into Elasticsearch. This mechanism has an inherent delay, so the index is always some time behind the actual update. But, thanks to the transfer queue mechanism, there is a guarantee that if a commit happened, Elasticsearch will eventually be updated.
System Workflows (19:10)
As soon as you can list workflows, your users will ask you to perform batch operations, for example "Terminate all flows which match this criteria started by $USER".
You could program this externally: make a list, get the id's save to a file and execute a script to terminate them. To execute this reliably, you'd use a workflow, and this is exactly what Temporal does internally. The Batch Operation Workflow is built into the core cluster like a "system workflow" - it could be implemented outside, but we brought it in because we wanted to provide this as part of the core cluster functionality.

So we now have a worker role that performs system workflows, like database scans and other long operations, using standard Temporal workflow abstractions.
Temporal architecture (20:10)
Now you can perhaps understand the full picture of Temporal's Architecture:
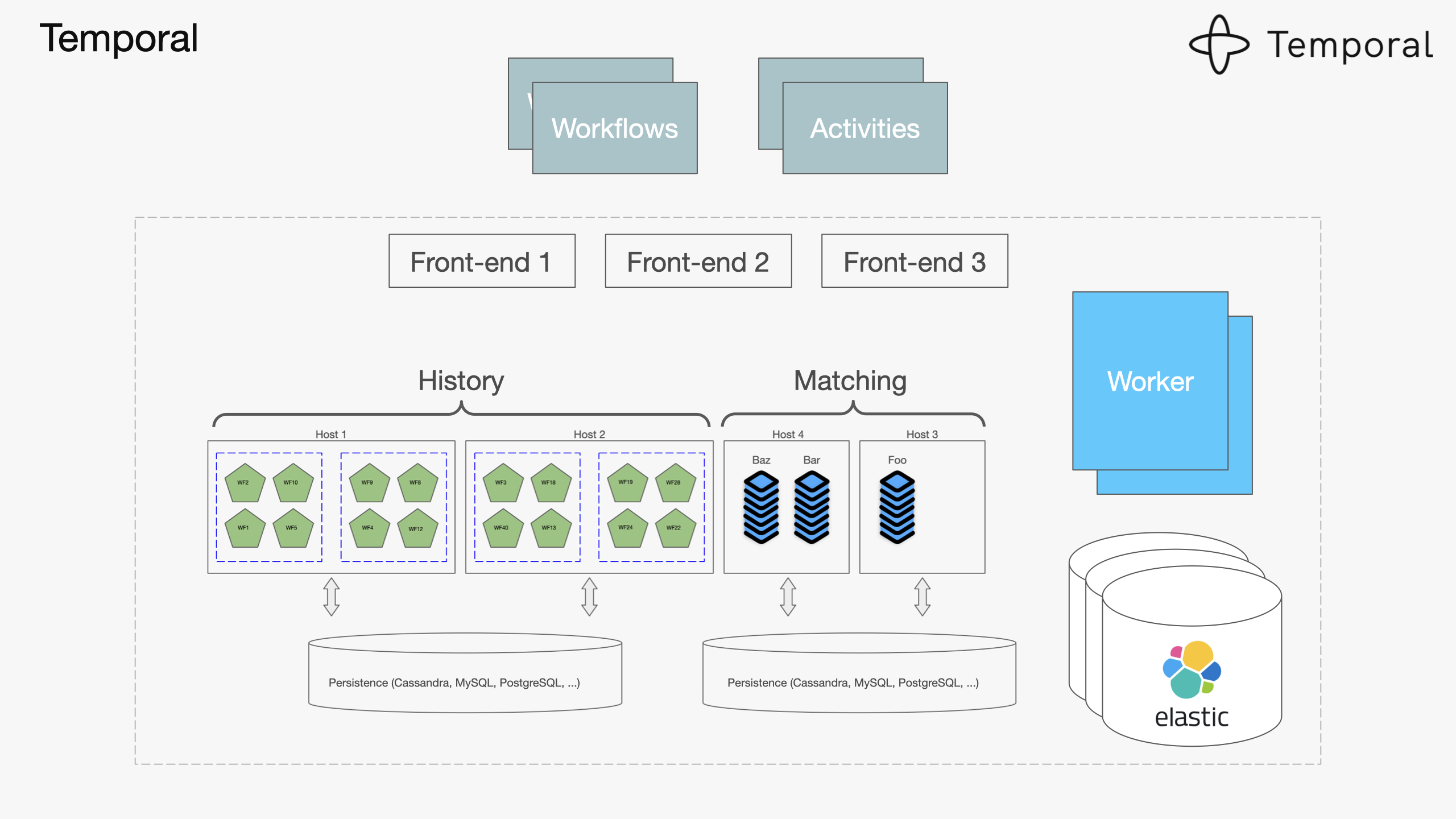
We have:
- the History component is responsible for state transitions of individual workflows
- we have Transfer Queues to be able to transactionally create tasks
- a Matching component responsible for delivering tasks for queuing and matching poll for requests coming from external workers
- a Front-end component because we need routing
- an Elastic component for indexing
- a Worker component for background jobs.
This leaves Workflows and Activities to be implemented by application developers using one of the Temporal SDKs.
Bonus: Multi-cluster Deployment (21:00)
This architecture is pretty scalable and reliable because every host can fail and it will still continue functioning:
- Shards, history, and matching will be redistributed automatically.
- Clustered databases like Cassandra can sustain node failures.
- Elasticsearch is fault tolerant.
- Frontends are stateless so you can add and remove them anytime
But the system still has a single point of failure in terms of blast radius, because a single bad schema deployment to the database can bring it down.
If you want to provide very high availability, we have multi-cluster deployment with asynchronous replication.

Even a total meltdown of the cluster or unavailability of a region will not stop your workflows, because you will be able to fail over your execution to another cluster and continue. This is a pretty complex part of the system - perhaps for the next talk!
Conclusion (22:15)
Temporal's appeal, apart from the workflow-as-code programming model, is that it is highly scalable and consistent, and allows external activities and workflow implementations outside of the cluster, which allows very high flexibility.
